Làm chủ Python Web Scraper trong 30 phút
Rảnh đời nên làm tiếp cái Tut cho mọi người về Python Web Scraper, bắt đầu luôn nhé!

Bắt đầu nào
Nếu đã cài đặt tất cả những yêu cầu trên của tớ thì bắt đầu nào!!!
Điều đầu tiên mà tớ sẽ sử dụng là sử dụng Selenium webdriver kết hợp với geckodriver để mở một cửa sổ trình duyệt làm việc. Để bắt đầu, hãy tạo một project ở Pycharm, mở tệp nén và kéo và thả tệp geckodriver vào thư mục project của bạn. Geckodriver sẽ cho phép Selenium "kiểm soát" Firefox, vì vậy chúng ta cần nó trong ở trong thư mục project của tớ để có thể sử dụng trình duyệt.
Tiếp theo điều tớ muốn làm là import các webdriver từ Selenium vào code và kết nối với URL:
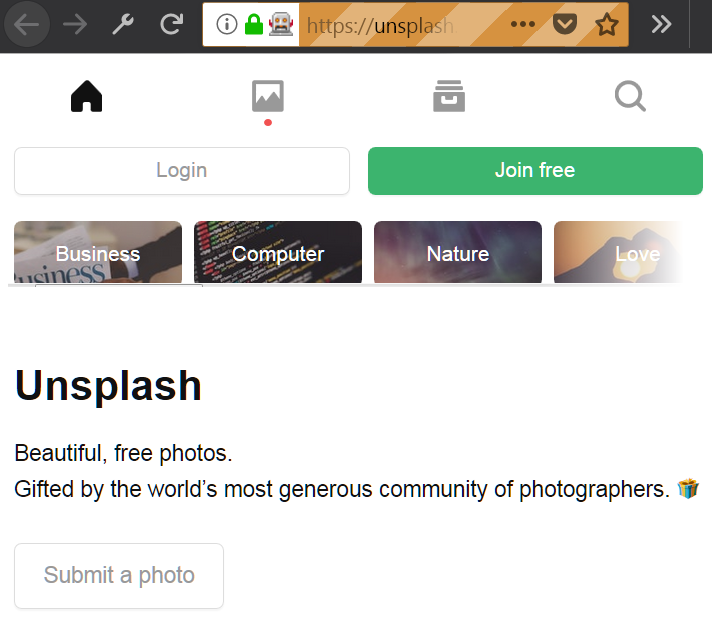
EZ không mấy bro, huh?
Nếu bạn đã làm tất cả mọi thứ chính xác, bạn sẽ thấy một cửa sổ trình duyệt tương tự như trong hình trên.
Tiếp theo, chúng ta nên cuộn xuống để có thể tải thêm hình ảnh trước khi ta download chúng. Hãy đợi một vài giây khi trong trường hợp mạng của bạn bị sida hoặc các hình ảnh đã không được tải đầy đủ
Khuyên bạn sử dụng Javascript để cuộn trang - tớ sẽ sử dụng window.scrollTo () để thực hiện việc này. Đặt tất cả lại với nhau, bạn sẽ có 1 đoạn code như thế này:
Điều tiếp theo chúng ta cần làm là tìm ra những hình ảnh mà mình muốn download từ trang web.
Sau khi "đào sâu" vào mã React mà ta vừa tạo ra, ta có thể sử dụng một chút ít CSS để nhắm mục tiêu cụ thể các hình ảnh trong thư viện của trang. Bố cục và code của trang có thể thay đổi trong tương lai, nhưng tại thời điểm viết tớ sử dụng bộ # gridMulti img để nhận tất cả các phần tử <img> xuất hiện trên màn hình.
Chúng ta có thể có được một danh sách các phần tử này sử dụng find_elements_by_css_selector (), nhưng những gì chúng ta muốn là thuộc tính src của mỗi phần tử. Vì vậy, chúng ta có thể lặp lại danh sách và lấy những điều đó:
BytesIO từ io sẽ được dùng để ghi các hình ảnh vào thư mục./images/ chúng ta sẽ tạo trong project của chúng tớ. Hãy đặt tất cả lại với nhau, chúng ta cần phải gửi yêu cầu HTTP GET tới URL của mỗi hình ảnh và sau đó, sử dụng
Web Scraper là gì ?
Web scraping là một quá trình tự động thu thập thông tin từ website. Kiểu scraping phổ biến nhất là site scraping, tập trung vào sao chép và đánh cắp nội dung web ( securitydaily)Cần chuẩn bị cái gì?
- Python (3.6.3 hoặc mới hơn)
- Pycharm
- pip install requests Pillow selenium
- geckodriver
- Firefox
- Kết nối internet ổn định (rõ ràng)
- 30 phút trong cuộc đời ngắn ngủi của bạn (có thể ít hơn)
Bắt đầu nào
Nếu đã cài đặt tất cả những yêu cầu trên của tớ thì bắt đầu nào!!!
Điều đầu tiên mà tớ sẽ sử dụng là sử dụng Selenium webdriver kết hợp với geckodriver để mở một cửa sổ trình duyệt làm việc. Để bắt đầu, hãy tạo một project ở Pycharm, mở tệp nén và kéo và thả tệp geckodriver vào thư mục project của bạn. Geckodriver sẽ cho phép Selenium "kiểm soát" Firefox, vì vậy chúng ta cần nó trong ở trong thư mục project của tớ để có thể sử dụng trình duyệt.
Tiếp theo điều tớ muốn làm là import các webdriver từ Selenium vào code và kết nối với URL:
from selenium import webdriver# The URL we want to browse tourl = "https://unsplash.com"# Using Selenium's webdriver to open the pagedriver = webdriver.Firefox(executable_path=r'geckodriver.exe')driver.get(url)
EZ không mấy bro, huh?
Nếu bạn đã làm tất cả mọi thứ chính xác, bạn sẽ thấy một cửa sổ trình duyệt tương tự như trong hình trên.
Tiếp theo, chúng ta nên cuộn xuống để có thể tải thêm hình ảnh trước khi ta download chúng. Hãy đợi một vài giây khi trong trường hợp mạng của bạn bị sida hoặc các hình ảnh đã không được tải đầy đủ
Khuyên bạn sử dụng Javascript để cuộn trang - tớ sẽ sử dụng window.scrollTo () để thực hiện việc này. Đặt tất cả lại với nhau, bạn sẽ có 1 đoạn code như thế này:
Sau khi chạy đoạn mã trên, bạn sẽ thấy trình duyệt cuộn xuống trang một chút.import timefrom selenium import webdriverurl = "https://unsplash.com"driver = webdriver.Firefox(executable_path=r'geckodriver.exe')driver.get(url)# Scroll page and wait 5 secondsdriver.execute_script("window.scrollTo(0,1000);")time.sleep(5)
Điều tiếp theo chúng ta cần làm là tìm ra những hình ảnh mà mình muốn download từ trang web.
Sau khi "đào sâu" vào mã React mà ta vừa tạo ra, ta có thể sử dụng một chút ít CSS để nhắm mục tiêu cụ thể các hình ảnh trong thư viện của trang. Bố cục và code của trang có thể thay đổi trong tương lai, nhưng tại thời điểm viết tớ sử dụng bộ # gridMulti img để nhận tất cả các phần tử <img> xuất hiện trên màn hình.
Chúng ta có thể có được một danh sách các phần tử này sử dụng find_elements_by_css_selector (), nhưng những gì chúng ta muốn là thuộc tính src của mỗi phần tử. Vì vậy, chúng ta có thể lặp lại danh sách và lấy những điều đó:
Next step tớ sẽ sử dụng cácimport timefrom selenium import webdriverurl = "https://unsplash.com"driver = webdriver.Firefox(executable_path=r'geckodriver.exe')driver.get(url)driver.execute_script("window.scrollTo(0,1000);")time.sleep(5)# Select image elements and print their URLsimage_elements = driver.find_elements_by_css_selector("#gridMulti img")for image_element in image_elements:image_url = image_element.get_attribute("src")print(image_url)
requests và một phần của gói PIL, Image.BytesIO từ io sẽ được dùng để ghi các hình ảnh vào thư mục./images/ chúng ta sẽ tạo trong project của chúng tớ. Hãy đặt tất cả lại với nhau, chúng ta cần phải gửi yêu cầu HTTP GET tới URL của mỗi hình ảnh và sau đó, sử dụng
Image and BytesIO, để lưu lại hình ảnh mà chúng ta nhận được. Và:import timeĐó là tất cả những gì bạn cần để có được một số hình ảnh miễn phí tải về chúc các bạn thành công, hãy share để ủng hộ tớ nhé!
from selenium import webdriver
from PIL import Image
from io import BytesIO
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)
image_elements = driver.find_elements_by_css_selector("#gridMulti img")
i = 0
for image_element in image_elements:
image_url = image_element.get_attribute("src")
# Send an HTTP GET request, get and save the image from the response
image_object = requests.get(image_url)
image = Image.open(BytesIO(image_object.content))
image.save("./images/image" + str(i) + "." + image.format, image.format)
i += 1


No comments: